How a Computer Detects Adverbs and Other Parts of Speech

Photo by Rock'n Roll Monkey on Unsplash
Which part of speech (noun, verb, adjective, etc.) causes you the most problems? Some writers, for example, tend to overuse adverbs.
Bob ran quickly and silently down the corridor. He literally didn't know what to do. Stopping by the window, he looked out unhappily.
Other writers start many sentences with personal pronouns.
He walked to the window and looked out. He sighed, thinking about Alice. He wondered where she was.
Still others overuse adjectives, have little variety in their choice of verbs, or misuse conjunctions. The first step towards fixing such problems is to identify all parts of speech in your text document. But how can we use a computer to label automatically each word in a text as noun, verb, preposition, etc.? In the domain of Natural Language Processing, this is a well-known problem, called Part-of-Speech Tagging.

To understand how part-of-speech taggers work, let's take adverb detection as an example, since "don't use too many adverbs" is a piece of advice often given to debuting writers.
First of all, what is an adverb? According to the OED, an adverb is "a word that's used to give information about a verb, adjective, or other adverb". Many adverbs end in -ly, but many don't. Think for example of very, often, fast, soon i or almost, all of which are adverbs. It therefore goes without saying that we cannot simply use the rule "all words ending in -ly" to detect adverbs.
Also, we can't simply construct a list of all possible adverbs, and then label as an adverb any word that appears in that list. That is because some words may or may not be adverbs depending on how they are used in a sentence. For example, in the sentence:
You sang very well
the word well is an adverb. In:
We got water from the well
it's a noun, while in:
Tears well up in my eyes
it's a verb. We therefore need a more sophisticated approach. This can be provided by Machine Learning techniques.
Machine Learning is the name statisticians and data scientists give to a collection of algorithms that allow computers to learn the way humans do, by observation and training. In particular, part-of-speech taggers use techniques from the machine-learning sub-domain known as Supervised Learning. This involves showing a computer examples of tasks that have already been successfully completed by a human. For example, in the case of a part-of-speech tagger, we show the computer many texts where all the words have already been labelled with the correct part of speech. Under the supervision of these man-made examples, the computer learns to correctly label the words in brand new, unlabelled texts.
Many different Machine Learning algorithms can be used for this task. Here, we'll concentrate on the Hidden Markov Model algorithm.
Note: The word hidden appears in the name of the model because the parts of speech can be considered hidden information which we want to access. (In more technical terms, the parts of speech are "hidden states" which generated the sequence of words we observe.)
The Hidden Markov Model has two main ingredients:
Ingredient 1: The model contains statistical information about the order in which parts of speech most commonly appear. For example, pronouns are very often followed by verbs, e.g. I went, you are, he sings, they hope are all pairs of words commonly found in English texts. On the other hand, pronouns are rarely followed by prepositions. Consider you under, she on, they off... Such pairs of words are rarely found together in English.
We can see that the probability that a verb follows a pronoun is high, but the probability that a preposition follows a pronoun is low. We can make similar statements about all other parts of speech. These probabilities are called transition probabilities, and the exact numerical values of the probabilities can be calculated by examining many English texts where the part of speech of each word has already been identified.
Ingredient 2: The model also contains statistical information about the probability of observing each word in our text, given certain part-of-speech labels. Somewhat counterinuitively, instead of calculating the probability the word well is an adverb, we calculate the probability that the next word is well, assuming we already know it's an adverb. That may sound like the exact opposite of our original tasks, but it's an essential step for the model!
These probabilities are called emission probabilities. Again, the exact numerical values are calculated using are pre-labelled English texts.
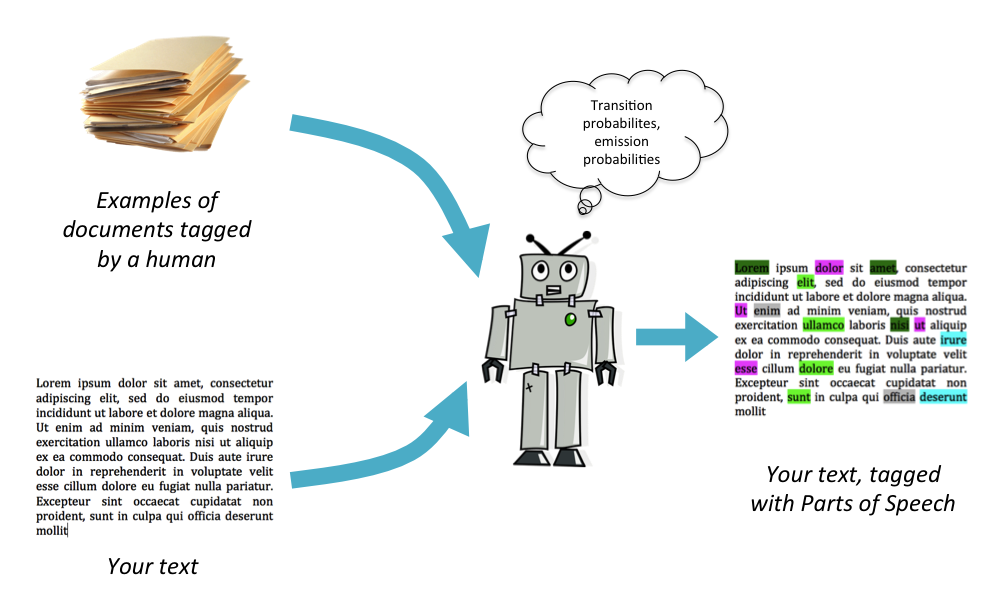
After training the computer (a.k.a. the machine learning model) to calculate all those probabilities, we can then analyse any English text.
The ZetaProse manuscript revision tool uses similar methods to identify the parts of speech in your uploaded text and calculate the percentage of your text that is composed of nouns, adverbs, adjectives and so on.
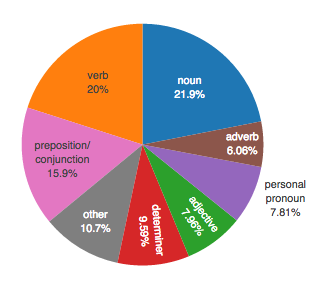

The above screenshots show examples of the tool's capabilities. You can try it out here.